

3.1 词法分析器的设计
词法分析(Lexical Analysis)/扫描(Scanning)
词法分析器读入源程序的字符流,将其组织成有意义的词素(Lexeme)序列,产生如下的词法单元作为输出:
<token-name, attribute-value>

查找已扫描字符串中最后一个对应于某终态的字符
- 找到终态字符,并将该字符与其前面的字符识别成一个单词。 随后将输入指针退回,扫描器重新回到初始状态, 继续识别下一个单词
- 无法找到终态字符,则确定出错,采用错误恢复策略。
- 从剩余的输入中不断删除字符, 直到词法分析器能够在 剩余输入的开头发现一个正确的字符为止(恐慌模式)
3.1.1 词法分析器的任务
- 从左至右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成为单词符号串的中间程序。
- 输入源程序,输出单词符号
- 过滤空白、换行、制表符、注释等
- 将词素添加到符号表中
与语法分析的关系如下:

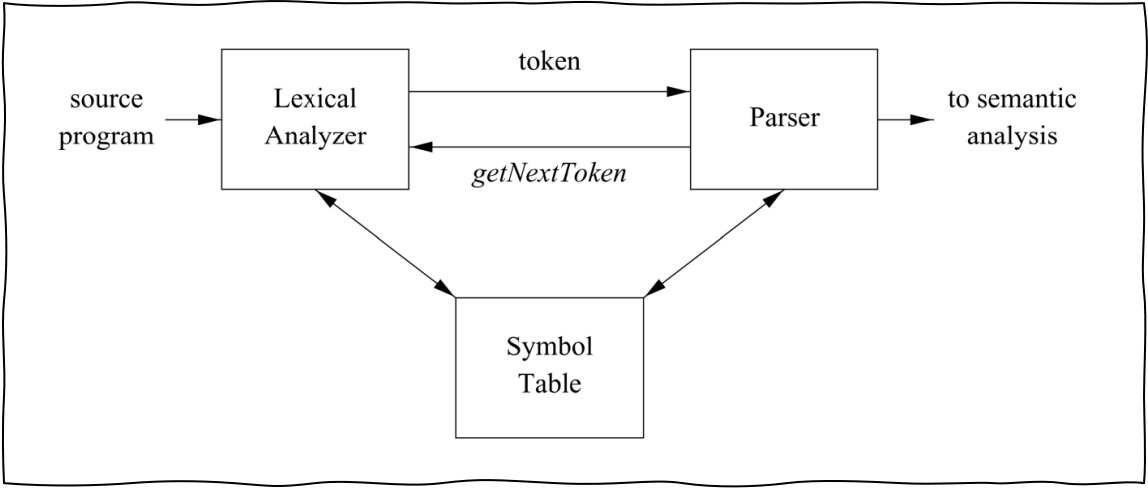
在逻辑上独立于语法分析,但是通常和语法分析器处于同一趟中。
独立的词法分析器可以:
- 简化编译器的设计(词法分析器可以首先完成一些简单的工作,原理简单)
- 提高编译器效率
- 增强编译器的可移植性
词法分析的任务
- 输入源程序
- 输出单词符号(词法单元)
- 词法规则表示:正则表达式
- 识别方法:有穷自动机
3.1.2 词法分析器的输出
词法单元 (Token)
<词法单元名、属性值 (可选) >
单元名是表示词法单位种类的抽象符号,语法分析器 通过单元名即可确定词法单元序列的结构

属性值通常用于语义分析之后的阶段
模式 (Pattern)
描述了一类词法单元的词素可能具有的形式
词素 (Lexeme)
源程序中的字符序列
它和某个词法单元的模式匹配,被词法分析器识别为该词法单元的实例
常用的程序语言词素可分为以下几类:
- 关键字:由程序语言定义的具有固定意义的标识符。也称为保留字或基本字。 关键字统归为一种,根据属性值分别是什么;也可以一字一种,一个关键字对应一个词法单元(常见)
- 标识符:用来表示程序中各种名字的字符串。统归为一种。
- 常数:常数的类型一般有整型、实型、布尔型、文字型。按类型(整、实、布尔等)分种。
- 运算符:如+、- 、*、/ 等。一符一种。
- 界符:如逗号、分号、括号等。一符一种。
3.2 识别词法单元

- LexemeBegin指针:指向当前词素的开始处。
- forward指针:一直向前扫描,直到发现某个模式被匹配为止。
一旦确定了下一个词素,forward指针将指向该词素结尾的字符。词法分析器将这个词素作为某个返回给语法分析器的词法单元的属性值记录下来。然后使LexemeBegin指针指向刚刚找到的词素之后的一个字符。
3.2.1 识别词法单元——状态转换图
一个状态转换图可用于识别(或接受)一定的字符串。

词法分析器的重要组件之一
状态转换图 (Transition diagram)
状态 (State):表示在识别词素时可能出现的情况
- 状态看作是已处理部分的总结
- 某些状态为接受状态或最终状态,表明已找到词素
- 加上*的接受状态表示最后读入的符号不在词素中
- 开始状态 (初始状态):用Start边表示
边 (Edge):从一个状态指向另一个状态
- 边的标号是一个或多个符号
- 当前状态为s,下一个输入符号为a,就沿着从s离开,标号为a的边到达下一个状态
3.3 正则表达式
语言 L={a}{a,b}*({ε}∪({.,_}{a,b}{a,b}*))
正则表达式(Regular Expression,RE ) 是一种用来描述正则语言的更紧凑的表示方法
例:
正则表达式可以由较小的正则表达式按照特定规则递归地 构建。每个正则表达式 r 定义(表示)一个语言,记为L(r )。 这个语言也是根据r 的子表达式所表示的语言递归定义的
3.3.1 定义
ε是一个RE(正则表达式), L(ε) = {ε}
如果 a∈∑ ,则a是一个RE正则表达式, L(a) = {a}
假设 r和 s都是 RE ,表示的语言分别是L(r)和L(s),则
- 选择:r|s 是一个RE, L( r|s ) = L(r)∪L(s)
- 连接:rs 是一个RE, L( rs ) = L(r) L(s)
- 闭包:r* 是一个RE,L( r*)= (L(r))*
- 括号:(r) 是一个RE, L( (r) ) = L(r)
运算的优先级(从大到小):* 、连接、| 例:(a)|((b)*(c))=a|b*c

C语言无符号整数的RE
- 十进制整数的RE:(1|...|9)(0|...|9) |0
- 八进制整数的RE:0(0|1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)
- 十六进制整数的RE:0x(0|1|...|9|a|...| f |A| … |F)(0|...|9|a|...| f |A| … |F )*
可以用RE 定义的语言叫做正则语言(regular language)或正则集合(regular set)
3.3.2 RE的代数定律
定律 | 描述 |
r|s = s|r | |是可以交换的 |
r|( s|t )= ( r|s )|t | |是可结合的 |
r( s t )=( r s )t | 连接是可结合的 |
r( s|t )= r s|r t ;
( s|t)r = s r|t r | 连接对|是可分配的 |
εr = rε = r | ε 是连接的单位元 |
r * =( r|ε )* | 闭包中一定包含 ε |
r **= r * | * 具有幂等性 |
3.3.3 正则文法与正则表达式等价
对任何正则文法 G,存在定义同一语言的正则表达式 r
对任何正则表达式 r,存在生成同一语言的正则文法 G
3.4 正则定义
给一些RE命名,并在之后的RE 中像使用字母表中的符号一样使用这些名字
正则定义是具有如下形式的定义序列:
d1 →r1
d2 →r2
…
dn →rn
其中:
每个di都是一个新符号,它们都不在字母表Σ 中,而且各不相同
每个ri 是字母表 Σ ∪{d1 ,d2 , … ,di-1}上的正则表达式)


3.5 有穷自动机 FA
FA包含NFA和DFA(要知道区别!)
是对一类处理系统建立的数学模型这类系统具有一系列离散的输入输出信息和有穷数目的内部状态 (状态:概括了对过去输入信息处理的状况)系统只需要根据当前所处的状态和当前面临的输入信息就可以决定系统的后继行为。每当系统处理了当前的输入后,系统的内部状态也将发生改变
3.5.1 FA介绍
FA模型

输入带(input tape):用来存放输入符号串
读头(head ): 从左向右逐个读取输入符号,不能修改(只读)、 不能往返移动
有穷控制器(finite control ): 具有有穷个状态数,根据当前的 状态和当前输入符号控制转入下一状态
FA的表示
转换图(Transition Graph)
结点: FA 的状态
初始状态(开始状态):只有一个,由start箭头指向
终止状态(接收状态):可以有多个,用双圈表示
带标记的有向边: 如果对于输入a,存在一个从状态p到状 态q的转换,就在p 、 q之间画一条有向边,并标记上a
FA定义(接收)的语言
- 给定输入串x ,如果存在一个对应于串x 的从初始状态 到某个终止状态的转换序列,则称串x 被该FA 接收
- 由一个有穷自动机M 接收的所有串构成的集合称为是 该FA 定义(或接收)的语言,记为L(M )

最长子串匹配原则 (Longest String Matching Principle)
当输入串的多个前缀与一个或多个模式匹配时, 总是选择最长的前缀进行匹配。

在到达某个终态之后,只要输入带上还有符号,DFA 就继续前进,以便寻找尽可能长的匹配
3.5.2 NFA和DFA
本质上和状态转换图相同,但有穷自动机只回答Yes/No。分为两类:
- 不确定的有穷自动机(Nondeterministicfinite automata, NFA):边上的标号没有限制,一个符号可出现在离开同一个状态的多条边上,ε可以做标号;
- 确定的有穷自动机(Deterministicfinite automata, DFA):对于每个状态以及每个符号,有且只有一条边(或最多只有一条边)
DFA是NFA的一个特例 FA边上的标号也就是字母表中的符号。
确定的有穷自动机 DFA


S:0 1 2 3 四个状态
输入字母表:a b
状态转换函数使用状态转换图表示
对于每一种状态,接受到某一种字符后状态的变化情况
非确定的有穷自动机 NFA


带有和不带有“ε-边”的NFA的等价性


DFA的算法实现
输入:以文件结束符eof结尾的字符串x。DFA D的开始状 态, 接收状态集 F ,转换函数move。
输出:如果D 接收 x,则回答“yes”,否则回答“no”
方法:将下述算法应用于输入串x。
函数nextChar( )返回输入串x的下 一个符号
函数move(s, c)表示从状态s出发,沿着标记为c的边所能到达的状态
DFA和NFA的等价性
会考给定一个DFA,写出最小的NFA
- 对任何非确定的有穷自动机N ,存在定义同一语言的确定的有穷自动机D
- 对任何确定的有穷自动机D ,存在定义同一语言的非确定的有穷自动机N

3.5.3 从正则表达式到有穷自动机
大题: ①给出描述写出正则表达式/直接给出正则表达式 ②NFA ③子集法转化为DFA ④DFA化简
1.正则表达式→NFA



2.NFA→DFA
方法一

方法二




3.DFA的化简

1、将S划分为终态(带着双圈的)和非终态两个子集,形成基本划分P
2、检查P中子集是否能进一步划分(基于状态a和b)









